ココで、「シャットダウン・リブート中に刺さったような現象が」って書いた。
コレ、どうやら iSCSIターゲットにログインしている状態(iSCSIディスクのLVMアクティベートは関係なく)でシャットダウンやリブートを行うと発生するようだ。
iSCSIターゲットからログアウトした状態でリブートした場合は発生しない。
ということは、ネットワーク切断後にiSCSIログアウトを行おうとしているんだろう。
今回の構成は、OpenvSwitchで作った仮想スイッチの先に iSCSIターゲットがあるが、普通に設計する場合は、iSCSI用に専用の物理ネットワークポートを用意(大抵は冗長化のため、複数ポート)する。
この場合、iSCSI専用NICには、OpenvSwitchのような仮想スイッチを挟むことはしないはずだ。
自宅で作っているような小さな環境の場合、データ用とiSCSI用でネットワークも分離せず、全て1系統のみで賄ってしまうような形になるだろう。
つまるところ、ウチの構成が、iSCSIターゲットを使う理想の構成からは外れている、ということだ。
恐らく、OpenvSwitchによる仮想スイッチの停止処理と、iSCSIターゲットからのログアウト処理の順序性の問題だと思われる。
となると、どうすればいいのだろうか?
そのあたりを中心に、ちょっと調査を継続しよう。
2017年4月25日火曜日
2017年4月24日月曜日
まずはiSCSIボリュームでocfs2/gfs2共有領域を
とりあえず、共有領域を作ろう。
以前、ココで100GBの ocfs2 用のボリュームは用意した。
とりあえず、コレを使って ocfs2 用の領域を作ろう。
multipath が正しく動いていれば、 /dev/mapper/ocfs2-001 というデバイスファイル名で見えているはずだ。(シンボリックリンクだけど、普通にデバイスファイルとして扱える。)
これを、クラスタマークを付与した /dev/vg-ocfs2 に追加し、既に存在するファイルシステムを pvmove で /dev/mapper/ocfs2-001 に移してしまう。
アクティベートされていないと思うので、アクティベートしておこう。
(gemini) $ sudo vgchange -asy vg-ocfs2
(gemini) $ sudo vgdisplay -v vg-ocfs2
/dev/mapper/ocfs2-001 を vg-ocfs2 に追加。
これまでは、parted による gptパーティション を作っていたが、今回はディスクデバイスごと追加してしまう。
(gemini) $ sudo pvcreate /dev/mapper/ocfs2-001
(gemini) $ sudo pvdisplay /dev/mapper/ocfs2-001
(gemini) $ sudo vgextend vg-ocfs2 /dev/mapper/ocfs2-001
(gemini) $ sudo vgdisplay -v vg-ocfs2
ここまで出来たら、cancer 側でも確認。
(cancer) $ sudo vgdisplay -v vg-ocfs2
ちょっと試しに、両ノードでマウントしておこう。
(gemini) $ sudo systemctl start /mnt/ocfs2
あ…あれ?マウント出来ねぇ…。
なんか、クラスタサービスがどうのこうの…
ヨクワカランが、o2cbサービスの再起動をしておく。
(gemini) $ sudo vgchange -a n vg-ocfs2
(gemini) $ sudo systemctl restart o2cb
(cancer) $ sudo systemctl restart o2cb
(gemini) $ sudo vgchange -asy vg-ocfs2
再びマウント
(gemini) $ sudo systemctl start /mnt/ocfs2
(cancer) $ sudo systemctl start /mnt/ocfs2
(gemini) $ df /mnt/ocfs2
(cancer) $ df /mnt/ocfs2
マウント出来ているのが確認できたら、vdb1 から ocfs2-001 へ移動。
(gemini) $ sudo pvmove /dev/vdb1 /dev/mapper/ocfs2-001
Cannot move in clustered VG vg-ocfs2, clustered mirror (cmirror) not detected and LVs are activated non-exclusively.
おや?どうやら、排他モードでアクティベートしていないと、pvmove は出来ないらしい。知らんかった。
(clusterd mirror というのを動かしておけばいいようだ。これも要調査だな。)
というわけで、一旦排他モードにする。
(cancer) $ sudo systemctl stop /mnt/ocfs2
(gemini) $ sudo systemctl stop /mnt/ocfs2
(gemini) $ sudo vgchange -an vg-ocfs2
(gemini) $ sudo vgchange -aey vg-ocfs2
(gemini) $ sudo systemctl start /mnt/ocfs2
そしたら今度こそ pvmove 。
(gmeini) $ sudo pvmove /dev/vdb1 /dev/mapper/ocfs2-001
う~ん。排他モードでないとダメなのかなぁ?他にやり方ありそうだけど…。
pvmoveが完了したら、状況を確認してみよう。
(gemini) $ ls /mnt/ocfs2
(gemini) $ sudo vgdisplay -v vg-ocfs2
(gemini) $ sudo pvdisplay -v /dev/vdb1
(gemini) $ sudo pvdisplay -v /dev/mapper/ocfs2-001
vgdisplayのタイミングで、vg構成のバックアップが行われたようだ。
本来なら、vgcfgbackup を実行する必要がありそうだな。(今回は自動で実行されたので不要だが)
cancer側でも確認。
(cancer) $ sudo vgcfgbackup vg-ocfs2
(cancer) $ sudo vgdisplay -v vg-ocfs2
(cancer) $ sudo pvdisplay -v /dev/vdb1
(cancer) $ sudo pvdisplay -v /dev/mapper/ocfs2-001
/dev/vdb1 の Allocated PE がゼロになっているのが確認できたら、この /dev/vdb1 は不要になったので、vg-ocfs2 から切り離そう。
(gemini) $ sudo vgreduce vg-ocfs2 /dev/vdb1
(gemini) $ sudo vgdisplay -v vg-ocfs2
(cancer) $ sudo vgdisplay -v vg-ocfs2
/dev/vdb1 の PVヘッダ(pvcreate コマンドでディスク上に付けられる管理情報)も削除しておこう。
(gemini) $ sudo pvdisplay /dev/vdb1
(cancer) $ sudo pvdisplay /dev/vdb1
(gemini) $ sudo pvremove /dev/vdb1
(gemini) $ sudo pvdisplay /dev/vdb1
(cancer) $ sudo pvdisplay /dev/vdb1
パーティションテーブルも削除。
(gemini) $ sudo parted /dev/vdb print
(cancer) $ sudo parted /dev/vdb print
(gemini) $ sudo parted /dev/vdb rm 1
(gemini) $ sudo parted /dev/vdb print
(cancer) $ sudo parted /dev/vdb print
削除が終わったら、/dev/vdb 自体をOSから外してしまおう。
(gemini) $ ls -l /sys/block/vdb/device
virtio4 へのシンボリックリンクのようだ。
(gemini) $ sudo bash -c "echo virtio4 > /sys/bus/virtio/drivers/virtio_blk/unbind"
(gemini) $ ls -l /dev/vdb*
(gemini) $ lsblk
cancerも。
(cancer) $ ls -l /sys/block/vdb/device
こちらも virtio4 へのシンボリックリンクのようだ。
(cancer) $ sudo bash -c "echo virtio4 > /sys/bus/virtio/drivers/virtio_blk/unbind"
(cancer) $ ls -l /dev/vdb*
(cancer) $ lsblk
そしたら、virt-manager を使って、仮想マシン gemini/cancer から当該仮想ディスクを外しておこう。
あっと、vg-ocfs2 は今、排他モードになっているはず。
共有モードに切り替えておこう。
(gemini) $ sudo systemctl stop /mnt/ocfs2
(gemini) $ sudo vgchange -a n vg-ocfs2
(gemini) $ sudo vgchange -asy vg-ocfs2
マウント出来るか確認。
(gemini) $ sudo systemctl start /mnt/ocfs2
(cancer) $ sudo systemctl start /mnt/ocfs2
構成をいじったので、再起動して反映されているか確認しておこう。
(gemini) $ sudo systemctl reboot
(cancer) $ sudo systemctl reboot
(gemini) $ lsblk
(cancer) $ lsblk
(gemini) $ sudo vgdisplay -v vg-ocfs2
(cancer) $ sudo vgdisplay -v vg-ocfs2
ここまで問題なし。
(gemini) $ sudo vgchange -asy vg-ocfs2
(gemini) $ sudo systemctl start /mnt/ocfs2
やっぱりマウントで失敗する。どうやら、o2cb の起動処理に問題がありそうだ。
別途調査。
取り急ぎ、o2cb の再起動で逃げよう。
(gemini) $ sudo systemctl restart o2cb
(cancer) $ sudo systemctl restart o2cb
も一回マウント
(gemini) $ sudo systemctl start /mnt/ocfs2
(cancer) $ sudo systemctl start /mnt/ocfs2
マウント出来た。
これで、iSCSI共有領域のみで ocfs2 のファイルシステムを用意できた。
共有用に使ってて、この作業で切り離した ocfs2.qcow2 は、virt-manager を使って削除しておこう。
-------------------------------------------------------
続いて、gfs2 領域もiSCSI化してしまおう。
やり方はまったく同じ。
まずは、NASキットの iSCSI ターゲット機能を使って、gemini/cancerに100GBのLUNを渡す。(gemini/cancerの両方と接続しているiSCSIターゲットに、100GBのLUNを追加する。)
dmesg コマンドで確認すると、gemini では /dev/sdc、cancer では /dev/sdb として認識された。
というわけで、gemini から作業。
(gemini) $ sudo cat /etc/multipath/wwids
(gemini) $ sudo multipath -a /dev/sdc
(gemini) $ sudo cat /etc/multipath/wwids
(gemini) $ sudo multipath -ll
(gemini) $ sudo multipath -r /dev/sdc
(gemini) $ sudo multipath -ll
(gemini) $ sudo vi /etc/multipath/bindings
--ココから
mpatha 23566633634646565
↓(新しく作成されたデバイスの名前を変更する。)
gfs2-001 23566633634646565
--ココまで
(gemini) $ sudo multipath -ll
(gemini) $ sudo multipath -F /dev/sdc
(gemini) $ sudo multipath -ll
(gemini) $ sudo multipath -r /dev/sdc
(gemini) $ sudo multipath -ll
これで、gemini では、新しいディスクは /dev/mapper/gfs2-001 というデバイスファイル名で扱えるようになった。
続いて、cancer 側で同じ作業。
(cancer) $ sudo cat /etc/multipath/wwids
(cancer) $ sudo multipath -a /dev/sdb
(cancer) $ sudo cat /etc/multipath/wwids
(cancer) $ sudo vi /etc/multipath/bindings
--ココから
(1行追加。)
gfs2-001 23566633634646565
--ココまで
(cancer) $ sudo multipath -ll
(cancer) $ sudo multipath -r /dev/sdb
(cancer) $ sudo multipath -ll
そしたら、ocfs2 と同じように移動作業。
ocfs2 の時は、排他モードでアクティベートしてから実施したけど、非アクティベート状態で実施する。
ただし、まだクラスタマークが付与されてなかったと思うので、クラスタマークは付与しておく。
(gemini) $ sudo vgdisplay -v vg-gfs2
(cancer) $ sudo vgdisplay -v vg-gfs2
(gemini) $ sudo vgchange -c y vg-gfs2
(gemini) $ sudo vgdisplay -v vg-gfs2
(cancer) $ sudo vgdisplay -v vg-gfs2
(gemini) $ sudo vgextend vg-gfs2 /dev/mapper/gfs2-001
(gemini) $ sudo vgdisplay -v vg-gfs2
(cancer) $ sudo vgdisplay -v vg-gfs2
(gemini) $ sudo pvmove /dev/vdb1 /dev/mapper/gfs2-001
(gemini) $ sudo vgdisplay -v vg-gfs2
(cancer) $ sudo vgdisplay -v vg-gfs2
ここまでで移動は完了のはず。
移動完了したので、古い方のボリュームは切り離す。
(gemini) $ sudo vgreduce vg-gfs2 /dev/vdb1
(gemini) $ sudo vgdisplay -v vg-gfs2
(cancer) $ sudo vgdisplay -v vg-gfs2
(gemini) $ sudo pvdisplay /dev/vdb1
(cancer) $ sudo pvdisplay /dev/vdb1
(gemini) $ sudo pvremove /dev/vdb1
(gemini) $ sudo pvdisplay /dev/vdb1
(cancer) $ sudo pvdisplay /dev/vdb1
(gemini) $ sudo parted /dev/vdb print
(cancer) $ sudo parted /dev/vdb print
(gemini) $ sudo parted /dev/vdb rm 1
(gemini) $ sudo parted /dev/vdb print
(cancer) $ sudo parted /dev/vdb print
(gemini) $ ls -l /sys/block/vdb/device
virtio4 へのシンボリックリンクのようだ。
(gemini) $ sudo bash -c "echo virtio4 > /sys/bus/virtio/drivers/virtio_blk/unbind"
(gemini) $ ls -l /dev/vdb*
(gemini) $ lsblk
(cancer) $ ls -l /sys/block/vdb/device
こちらも virtio4 へのシンボリックリンクのようだ。
(cancer) $ sudo bash -c "echo virtio4 > /sys/bus/virtio/drivers/virtio_blk/unbind"
(cancer) $ ls -l /dev/vdb*
(cancer) $ lsblk
そしたら、virt-manager を使って、仮想マシン gemini/cancer から当該仮想ディスクを外しておこう。
vg-gfs2 を共有モードでアクティベートして確認だ。
(gemini) $ sudo vgchange -a n vg-gfs2
(gemini) $ sudo vgchange -asy vg-gfs2
マウント出来るか確認。
(gemini) $ sudo systemctl start /mnt/gfs2
(cancer) $ sudo systemctl start /mnt/gfs2
構成をいじったので、再起動して反映されているか確認しておこう。
(gemini) $ sudo systemctl reboot
(cancer) $ sudo systemctl reboot
あれ?ココで cancer のシャットダウン処理中に刺さる現象が…。
ネットワーク関連っぽいな。cifs マウントか iSCSI 関連が絡んでいそうだ。
これも要調査。
とりあえず、cancer は強制的に再起動させた。
(gemini) $ lsblk
(cancer) $ lsblk
(gemini) $ sudo vgdisplay -v vg-gfs2
(cancer) $ sudo vgdisplay -v vg-gfs2
(gemini) $ sudo vgchange -asy vg-gfs2
(gemini) $ sudo systemctl start /mnt/gfs2
(cancer) $ sudo systemctl start /mnt/gfs2
マウント出来た。
これで、iSCSI共有領域のみで ocfs2 のファイルシステムを用意できた。
ocfs2 の時と同様、共有用に使ってて、この作業で切り離した gfs2.qcow2 は、virt-manager を使って削除しておこう。
さて、ココまでで iSCSI 領域の共有化が完成したが、問題が3点。
これらも調査を継続しないと…な…。
以前、ココで100GBの ocfs2 用のボリュームは用意した。
とりあえず、コレを使って ocfs2 用の領域を作ろう。
multipath が正しく動いていれば、 /dev/mapper/ocfs2-001 というデバイスファイル名で見えているはずだ。(シンボリックリンクだけど、普通にデバイスファイルとして扱える。)
これを、クラスタマークを付与した /dev/vg-ocfs2 に追加し、既に存在するファイルシステムを pvmove で /dev/mapper/ocfs2-001 に移してしまう。
アクティベートされていないと思うので、アクティベートしておこう。
(gemini) $ sudo vgchange -asy vg-ocfs2
(gemini) $ sudo vgdisplay -v vg-ocfs2
/dev/mapper/ocfs2-001 を vg-ocfs2 に追加。
これまでは、parted による gptパーティション を作っていたが、今回はディスクデバイスごと追加してしまう。
(gemini) $ sudo pvcreate /dev/mapper/ocfs2-001
(gemini) $ sudo pvdisplay /dev/mapper/ocfs2-001
(gemini) $ sudo vgextend vg-ocfs2 /dev/mapper/ocfs2-001
(gemini) $ sudo vgdisplay -v vg-ocfs2
ここまで出来たら、cancer 側でも確認。
(cancer) $ sudo vgdisplay -v vg-ocfs2
ちょっと試しに、両ノードでマウントしておこう。
(gemini) $ sudo systemctl start /mnt/ocfs2
あ…あれ?マウント出来ねぇ…。
なんか、クラスタサービスがどうのこうの…
ヨクワカランが、o2cbサービスの再起動をしておく。
(gemini) $ sudo vgchange -a n vg-ocfs2
(gemini) $ sudo systemctl restart o2cb
(cancer) $ sudo systemctl restart o2cb
(gemini) $ sudo vgchange -asy vg-ocfs2
再びマウント
(gemini) $ sudo systemctl start /mnt/ocfs2
(cancer) $ sudo systemctl start /mnt/ocfs2
(gemini) $ df /mnt/ocfs2
(cancer) $ df /mnt/ocfs2
マウント出来ているのが確認できたら、vdb1 から ocfs2-001 へ移動。
(gemini) $ sudo pvmove /dev/vdb1 /dev/mapper/ocfs2-001
Cannot move in clustered VG vg-ocfs2, clustered mirror (cmirror) not detected and LVs are activated non-exclusively.
おや?どうやら、排他モードでアクティベートしていないと、pvmove は出来ないらしい。知らんかった。
(clusterd mirror というのを動かしておけばいいようだ。これも要調査だな。)
というわけで、一旦排他モードにする。
(cancer) $ sudo systemctl stop /mnt/ocfs2
(gemini) $ sudo systemctl stop /mnt/ocfs2
(gemini) $ sudo vgchange -an vg-ocfs2
(gemini) $ sudo vgchange -aey vg-ocfs2
(gemini) $ sudo systemctl start /mnt/ocfs2
そしたら今度こそ pvmove 。
(gmeini) $ sudo pvmove /dev/vdb1 /dev/mapper/ocfs2-001
う~ん。排他モードでないとダメなのかなぁ?他にやり方ありそうだけど…。
pvmoveが完了したら、状況を確認してみよう。
(gemini) $ ls /mnt/ocfs2
(gemini) $ sudo vgdisplay -v vg-ocfs2
(gemini) $ sudo pvdisplay -v /dev/vdb1
(gemini) $ sudo pvdisplay -v /dev/mapper/ocfs2-001
vgdisplayのタイミングで、vg構成のバックアップが行われたようだ。
本来なら、vgcfgbackup を実行する必要がありそうだな。(今回は自動で実行されたので不要だが)
cancer側でも確認。
(cancer) $ sudo vgcfgbackup vg-ocfs2
(cancer) $ sudo vgdisplay -v vg-ocfs2
(cancer) $ sudo pvdisplay -v /dev/vdb1
(cancer) $ sudo pvdisplay -v /dev/mapper/ocfs2-001
/dev/vdb1 の Allocated PE がゼロになっているのが確認できたら、この /dev/vdb1 は不要になったので、vg-ocfs2 から切り離そう。
(gemini) $ sudo vgreduce vg-ocfs2 /dev/vdb1
(gemini) $ sudo vgdisplay -v vg-ocfs2
(cancer) $ sudo vgdisplay -v vg-ocfs2
/dev/vdb1 の PVヘッダ(pvcreate コマンドでディスク上に付けられる管理情報)も削除しておこう。
(gemini) $ sudo pvdisplay /dev/vdb1
(cancer) $ sudo pvdisplay /dev/vdb1
(gemini) $ sudo pvremove /dev/vdb1
(gemini) $ sudo pvdisplay /dev/vdb1
(cancer) $ sudo pvdisplay /dev/vdb1
パーティションテーブルも削除。
(gemini) $ sudo parted /dev/vdb print
(cancer) $ sudo parted /dev/vdb print
(gemini) $ sudo parted /dev/vdb rm 1
(gemini) $ sudo parted /dev/vdb print
(cancer) $ sudo parted /dev/vdb print
削除が終わったら、/dev/vdb 自体をOSから外してしまおう。
(gemini) $ ls -l /sys/block/vdb/device
virtio4 へのシンボリックリンクのようだ。
(gemini) $ sudo bash -c "echo virtio4 > /sys/bus/virtio/drivers/virtio_blk/unbind"
(gemini) $ ls -l /dev/vdb*
(gemini) $ lsblk
cancerも。
(cancer) $ ls -l /sys/block/vdb/device
こちらも virtio4 へのシンボリックリンクのようだ。
(cancer) $ sudo bash -c "echo virtio4 > /sys/bus/virtio/drivers/virtio_blk/unbind"
(cancer) $ ls -l /dev/vdb*
(cancer) $ lsblk
そしたら、virt-manager を使って、仮想マシン gemini/cancer から当該仮想ディスクを外しておこう。
あっと、vg-ocfs2 は今、排他モードになっているはず。
共有モードに切り替えておこう。
(gemini) $ sudo systemctl stop /mnt/ocfs2
(gemini) $ sudo vgchange -a n vg-ocfs2
(gemini) $ sudo vgchange -asy vg-ocfs2
マウント出来るか確認。
(gemini) $ sudo systemctl start /mnt/ocfs2
(cancer) $ sudo systemctl start /mnt/ocfs2
構成をいじったので、再起動して反映されているか確認しておこう。
(gemini) $ sudo systemctl reboot
(cancer) $ sudo systemctl reboot
(gemini) $ lsblk
(cancer) $ lsblk
(gemini) $ sudo vgdisplay -v vg-ocfs2
(cancer) $ sudo vgdisplay -v vg-ocfs2
ここまで問題なし。
(gemini) $ sudo vgchange -asy vg-ocfs2
(gemini) $ sudo systemctl start /mnt/ocfs2
やっぱりマウントで失敗する。どうやら、o2cb の起動処理に問題がありそうだ。
別途調査。
取り急ぎ、o2cb の再起動で逃げよう。
(gemini) $ sudo systemctl restart o2cb
(cancer) $ sudo systemctl restart o2cb
も一回マウント
(gemini) $ sudo systemctl start /mnt/ocfs2
(cancer) $ sudo systemctl start /mnt/ocfs2
マウント出来た。
これで、iSCSI共有領域のみで ocfs2 のファイルシステムを用意できた。
共有用に使ってて、この作業で切り離した ocfs2.qcow2 は、virt-manager を使って削除しておこう。
-------------------------------------------------------
続いて、gfs2 領域もiSCSI化してしまおう。
やり方はまったく同じ。
まずは、NASキットの iSCSI ターゲット機能を使って、gemini/cancerに100GBのLUNを渡す。(gemini/cancerの両方と接続しているiSCSIターゲットに、100GBのLUNを追加する。)
dmesg コマンドで確認すると、gemini では /dev/sdc、cancer では /dev/sdb として認識された。
というわけで、gemini から作業。
(gemini) $ sudo cat /etc/multipath/wwids
(gemini) $ sudo multipath -a /dev/sdc
(gemini) $ sudo cat /etc/multipath/wwids
(gemini) $ sudo multipath -ll
(gemini) $ sudo multipath -r /dev/sdc
(gemini) $ sudo multipath -ll
(gemini) $ sudo vi /etc/multipath/bindings
--ココから
mpatha 23566633634646565
↓(新しく作成されたデバイスの名前を変更する。)
gfs2-001 23566633634646565
--ココまで
(gemini) $ sudo multipath -ll
(gemini) $ sudo multipath -F /dev/sdc
(gemini) $ sudo multipath -ll
(gemini) $ sudo multipath -r /dev/sdc
(gemini) $ sudo multipath -ll
これで、gemini では、新しいディスクは /dev/mapper/gfs2-001 というデバイスファイル名で扱えるようになった。
続いて、cancer 側で同じ作業。
(cancer) $ sudo cat /etc/multipath/wwids
(cancer) $ sudo multipath -a /dev/sdb
(cancer) $ sudo cat /etc/multipath/wwids
(cancer) $ sudo vi /etc/multipath/bindings
--ココから
(1行追加。)
gfs2-001 23566633634646565
--ココまで
(cancer) $ sudo multipath -ll
(cancer) $ sudo multipath -r /dev/sdb
(cancer) $ sudo multipath -ll
そしたら、ocfs2 と同じように移動作業。
ocfs2 の時は、排他モードでアクティベートしてから実施したけど、非アクティベート状態で実施する。
ただし、まだクラスタマークが付与されてなかったと思うので、クラスタマークは付与しておく。
(gemini) $ sudo vgdisplay -v vg-gfs2
(cancer) $ sudo vgdisplay -v vg-gfs2
(gemini) $ sudo vgchange -c y vg-gfs2
(gemini) $ sudo vgdisplay -v vg-gfs2
(cancer) $ sudo vgdisplay -v vg-gfs2
(gemini) $ sudo vgextend vg-gfs2 /dev/mapper/gfs2-001
(gemini) $ sudo vgdisplay -v vg-gfs2
(cancer) $ sudo vgdisplay -v vg-gfs2
(gemini) $ sudo pvmove /dev/vdb1 /dev/mapper/gfs2-001
(gemini) $ sudo vgdisplay -v vg-gfs2
(cancer) $ sudo vgdisplay -v vg-gfs2
ここまでで移動は完了のはず。
移動完了したので、古い方のボリュームは切り離す。
(gemini) $ sudo vgreduce vg-gfs2 /dev/vdb1
(gemini) $ sudo vgdisplay -v vg-gfs2
(cancer) $ sudo vgdisplay -v vg-gfs2
(gemini) $ sudo pvdisplay /dev/vdb1
(cancer) $ sudo pvdisplay /dev/vdb1
(gemini) $ sudo pvremove /dev/vdb1
(gemini) $ sudo pvdisplay /dev/vdb1
(cancer) $ sudo pvdisplay /dev/vdb1
(gemini) $ sudo parted /dev/vdb print
(cancer) $ sudo parted /dev/vdb print
(gemini) $ sudo parted /dev/vdb rm 1
(gemini) $ sudo parted /dev/vdb print
(cancer) $ sudo parted /dev/vdb print
(gemini) $ ls -l /sys/block/vdb/device
virtio4 へのシンボリックリンクのようだ。
(gemini) $ sudo bash -c "echo virtio4 > /sys/bus/virtio/drivers/virtio_blk/unbind"
(gemini) $ ls -l /dev/vdb*
(gemini) $ lsblk
(cancer) $ ls -l /sys/block/vdb/device
こちらも virtio4 へのシンボリックリンクのようだ。
(cancer) $ sudo bash -c "echo virtio4 > /sys/bus/virtio/drivers/virtio_blk/unbind"
(cancer) $ ls -l /dev/vdb*
(cancer) $ lsblk
そしたら、virt-manager を使って、仮想マシン gemini/cancer から当該仮想ディスクを外しておこう。
vg-gfs2 を共有モードでアクティベートして確認だ。
(gemini) $ sudo vgchange -a n vg-gfs2
(gemini) $ sudo vgchange -asy vg-gfs2
マウント出来るか確認。
(gemini) $ sudo systemctl start /mnt/gfs2
(cancer) $ sudo systemctl start /mnt/gfs2
構成をいじったので、再起動して反映されているか確認しておこう。
(gemini) $ sudo systemctl reboot
(cancer) $ sudo systemctl reboot
あれ?ココで cancer のシャットダウン処理中に刺さる現象が…。
ネットワーク関連っぽいな。cifs マウントか iSCSI 関連が絡んでいそうだ。
これも要調査。
とりあえず、cancer は強制的に再起動させた。
(gemini) $ lsblk
(cancer) $ lsblk
(gemini) $ sudo vgdisplay -v vg-gfs2
(cancer) $ sudo vgdisplay -v vg-gfs2
(gemini) $ sudo vgchange -asy vg-gfs2
(gemini) $ sudo systemctl start /mnt/gfs2
(cancer) $ sudo systemctl start /mnt/gfs2
マウント出来た。
これで、iSCSI共有領域のみで ocfs2 のファイルシステムを用意できた。
ocfs2 の時と同様、共有用に使ってて、この作業で切り離した gfs2.qcow2 は、virt-manager を使って削除しておこう。
さて、ココまでで iSCSI 領域の共有化が完成したが、問題が3点。
- ocfs2ファイルシステムのマウントが出来ない
(o2cb.service を再起動させることで処理可能) - 再起動時に刺さる現象がまだ解消できていない
(ネットワークとネットワークストレージの関連か?) - CLVM共有モードで pvmove するためには、 clusterd mirror というのが必要
これらも調査を継続しないと…な…。
2017年4月23日日曜日
今後の予定
とりあえず、今後直近でやっておきたいことをリストアップ。
これは美味しくないので、この原因追求と、正しい設定の確認がしたい。
共有ボリュームを用いたKVM環境は、ノード間のオンラインマイグレーションと、片方のノードがダウンした時に、もう片方のノードでゲストを起動する、という動作の確認がしたい。
これらが落ち着いたら、また更にやりたいことがあるけど、とりあえずはこの2つかな。
- 2つのゲストOS(gemini/cancer)で共有ボリュームを用いたKVM環境構築
- dlm/corosyncのフェンシングについて調査
これは美味しくないので、この原因追求と、正しい設定の確認がしたい。
共有ボリュームを用いたKVM環境は、ノード間のオンラインマイグレーションと、片方のノードがダウンした時に、もう片方のノードでゲストを起動する、という動作の確認がしたい。
これらが落ち着いたら、また更にやりたいことがあるけど、とりあえずはこの2つかな。
2017年4月21日金曜日
cancerをgeminiと同格までセットアップ
ずっと gemini でセットアップを行っていたので、今は gemini と cancer のセットアップ情報に差異がある。
gemini である程度問題解決が出来たので、cancer を gemini と同程度になるようにセットアップすることにする。
ダダっと書いていく。
(cancer) $ sudo apt-get update
(cancer) $ sudo apt-get install qemu-kvm
(cancer) $ sudo systemctl reboot
(cancer) $ grep kvm /etc/group
(cancer) $ id
(cancer) $ sudo adduser (自分のユーザ名) kvm
(cancer) $ grep kvm /etc/group
(一旦exitで抜けて、再度ログイン)
(cancer) $ id
(cancer) $ lsmod | grep kvm
(cancer) $ sudo apt-get install virtinst libosinfo-bin virt-manager fonts-ipafont
(cancer) $ sudo systemctl reboot
再ログイン
(cancer) $ virsh list --all
(cancer) $ sudo apt-get install openvswitch-switch
(cancer) $ sudo ovs-vsctl show
(cancer) $ sudo ovs-vsctl list-br
(cancer) $ sudo ovs-vsctl add-br extsw
(cancer) $ sudo ovs-vsctl show
(cancer) $ sudo ovs-vsctl list-br
(cancer) $ cd /lib/systemd/system
(cancer) $ sudo cp -pi corosync.service corosync.service.orig
(cancer) $ sudo cp -pi openvswitch-switch.service openvswitch-switch.service.orig
(cancer) $ sudo vi corosync.service
--ココから
Requires=network-online.target
After=network-online.target
↓(前提条件に openvswitch-switch.service を追加する)
Requires=network-online.target openvswitch-switch.service
After=network-online.target openvswitch-switch.service
--ココまで
(cancer) $ sudo vi openvswitch-switch.service
--ココから
ExecStart=/bin/true
↓(何も実行しない処理を、6秒待機に変更する)
ExecStart=/bin/sleep 6
--ココまで
(cancer) $ cd
(cancer) $ sudo vi /etc/network/interfaces.d/0110.ens3
ファイルの新規作成
--ココから--
auto ens3
allow-extsw
iface ens3 inet manual
ovs_bridge extsw
ovs_type OVSPort
--ココまで--
(cancer) $ sudo vi /etc/network/interfaces.d/0010.extsw
ファイルの新規作成
--ココから--
auto extsw
allow-ovs extsw
iface extsw inet static
address 192.168.55.137
network 192.168.55.0
netmask 255.255.255.0
broadcast 192.168.55.255
gateway 192.168.55.1
ovs_type OVSBridge
ovs_ports ens3
dns-nameservers 192.168.55.1
--ココまで--
ネットワークセッションが切れてしまうので、コンソールで作業しよう。
(cancer) $ sudo ifdown ens3
(cancer) $ sudo rm /etc/network/interfaces.d/ens3
(cancer) $ sudo ovs-vsctl add-port extsw ens3
(cancer) $ sudo ovs-vsctl show
(cancer) $ sudo ifup ens3
(cancer) $ sudo ifup extsw
変更内容を取り込む。
(cancer) $ sudo systemctl daemon-reload
(cancer) $ sudo systemctl reboot
コンソール作業はココまで
(cancer) $ ip address show
(cancer) $ dig www.blogger.com
(cancer) $ sudo ovs-vsctl show
(cancer) $ virsh net-list --all
(cancer) $ vi ovsbridge.xml
ファイルの新規作成
--ここから
<network>
<name>ovsbridge</name>
<forward mode='bridge'/>
<bridge name='extsw'/>
<virtualport type='openvswitch'/>
</network>
--ここまで
(cancer) $ virsh net-define ovsbridge.xml
(cancer) $ virsh net-list --all
(cancer) $ virsh net-autostart ovsbridge
(cancer) $ virsh net-start ovsbridge
(cancer) $ virsh net-list --all
(cancer) $ sudo apt-get install ovmf
gemini はココで gemini 専用の iSCSIターゲット、LUN を作って作業を行ったが、cancer に対しては実施しないでおく。
(cancer) $ sudo apt-get install cifs-utils
(cancer) $ sudo mkdir /mnt/iso-os
fstabに追記する。
(cancer) $ sudo vi /etc/fstab
以下の行を追記
--ココから
//(cifsのIPアドレス)/(cifsのディレクトリ) /mnt/iso-os cifs guest,_netdev 0 0
--ココまで
マウント確認
(cancer) $ sudo mount /mnt/iso-os
(cancer) $ df /mnt/iso-os
(cancer) $ sudo umount /mnt/iso-os
再起動してマウント状態の確認
(cancer) $ sudo systemctl reboot
(cancer) $ df
(cancer) $ sudo cp -pi /etc/default/networking /etc/default/netwoking.orig
(cancer) $ sudo vi /etc/default/networking
--ココから
8行目付近
#EXCLUDE_INTERFACES=
↓(extswを指定)
EXCLUDE_INTERFACES=extsw
--ココまで
(cancer) $ systemctl is-enabled clvm
(cancer) $ sudo systemctl disable clvm
(cancer) $ systemctl is-enabled clvm
(cancer) $ sudo systemctl daemon-reload
(cancer) $ sudo systemctl reboot
こんなところかな?
gemini である程度問題解決が出来たので、cancer を gemini と同程度になるようにセットアップすることにする。
ダダっと書いていく。
(cancer) $ sudo apt-get update
(cancer) $ sudo apt-get install qemu-kvm
(cancer) $ sudo systemctl reboot
(cancer) $ grep kvm /etc/group
(cancer) $ id
(cancer) $ sudo adduser (自分のユーザ名) kvm
(cancer) $ grep kvm /etc/group
(一旦exitで抜けて、再度ログイン)
(cancer) $ id
(cancer) $ lsmod | grep kvm
(cancer) $ sudo apt-get install virtinst libosinfo-bin virt-manager fonts-ipafont
(cancer) $ sudo systemctl reboot
再ログイン
(cancer) $ virsh list --all
(cancer) $ sudo apt-get install openvswitch-switch
(cancer) $ sudo ovs-vsctl show
(cancer) $ sudo ovs-vsctl list-br
(cancer) $ sudo ovs-vsctl add-br extsw
(cancer) $ sudo ovs-vsctl show
(cancer) $ sudo ovs-vsctl list-br
(cancer) $ cd /lib/systemd/system
(cancer) $ sudo cp -pi corosync.service corosync.service.orig
(cancer) $ sudo cp -pi openvswitch-switch.service openvswitch-switch.service.orig
(cancer) $ sudo vi corosync.service
--ココから
Requires=network-online.target
After=network-online.target
↓(前提条件に openvswitch-switch.service を追加する)
Requires=network-online.target openvswitch-switch.service
After=network-online.target openvswitch-switch.service
--ココまで
(cancer) $ sudo vi openvswitch-switch.service
--ココから
ExecStart=/bin/true
↓(何も実行しない処理を、6秒待機に変更する)
ExecStart=/bin/sleep 6
--ココまで
(cancer) $ cd
(cancer) $ sudo vi /etc/network/interfaces.d/0110.ens3
ファイルの新規作成
--ココから--
auto ens3
allow-extsw
iface ens3 inet manual
ovs_bridge extsw
ovs_type OVSPort
--ココまで--
(cancer) $ sudo vi /etc/network/interfaces.d/0010.extsw
ファイルの新規作成
--ココから--
auto extsw
allow-ovs extsw
iface extsw inet static
address 192.168.55.137
network 192.168.55.0
netmask 255.255.255.0
broadcast 192.168.55.255
gateway 192.168.55.1
ovs_type OVSBridge
ovs_ports ens3
dns-nameservers 192.168.55.1
--ココまで--
ネットワークセッションが切れてしまうので、コンソールで作業しよう。
(cancer) $ sudo ifdown ens3
(cancer) $ sudo rm /etc/network/interfaces.d/ens3
(cancer) $ sudo ovs-vsctl add-port extsw ens3
(cancer) $ sudo ovs-vsctl show
(cancer) $ sudo ifup ens3
(cancer) $ sudo ifup extsw
変更内容を取り込む。
(cancer) $ sudo systemctl daemon-reload
(cancer) $ sudo systemctl reboot
コンソール作業はココまで
(cancer) $ ip address show
(cancer) $ dig www.blogger.com
(cancer) $ sudo ovs-vsctl show
(cancer) $ virsh net-list --all
(cancer) $ vi ovsbridge.xml
ファイルの新規作成
--ここから
<network>
<name>ovsbridge</name>
<forward mode='bridge'/>
<bridge name='extsw'/>
<virtualport type='openvswitch'/>
</network>
--ここまで
(cancer) $ virsh net-define ovsbridge.xml
(cancer) $ virsh net-list --all
(cancer) $ virsh net-autostart ovsbridge
(cancer) $ virsh net-start ovsbridge
(cancer) $ virsh net-list --all
(cancer) $ sudo apt-get install ovmf
gemini はココで gemini 専用の iSCSIターゲット、LUN を作って作業を行ったが、cancer に対しては実施しないでおく。
(cancer) $ sudo apt-get install cifs-utils
(cancer) $ sudo mkdir /mnt/iso-os
fstabに追記する。
(cancer) $ sudo vi /etc/fstab
以下の行を追記
--ココから
//(cifsのIPアドレス)/(cifsのディレクトリ) /mnt/iso-os cifs guest,_netdev 0 0
--ココまで
マウント確認
(cancer) $ sudo mount /mnt/iso-os
(cancer) $ df /mnt/iso-os
(cancer) $ sudo umount /mnt/iso-os
再起動してマウント状態の確認
(cancer) $ sudo systemctl reboot
(cancer) $ df
(cancer) $ sudo cp -pi /etc/default/networking /etc/default/netwoking.orig
(cancer) $ sudo vi /etc/default/networking
--ココから
8行目付近
#EXCLUDE_INTERFACES=
↓(extswを指定)
EXCLUDE_INTERFACES=extsw
--ココまで
(cancer) $ systemctl is-enabled clvm
(cancer) $ sudo systemctl disable clvm
(cancer) $ systemctl is-enabled clvm
(cancer) $ sudo systemctl daemon-reload
(cancer) $ sudo systemctl reboot
こんなところかな?
仮想スイッチ名変更(br-external→extsw)
さて、ある程度問題が落ち着いたところで、仮想スイッチ br-external の名前を変えようと思う。
以下のコマンドを実行してみると分かるが、デバイス名に"-"が入っていると、その部分が"\x2d"という文字に置き換わってしまい、ちょっと見にくい。
(gemini) $ systemctl | grep external
(マウントポイントに"-"が入っている場合なども…)
なので、これの名前を"-"が入っていない内容に変更してみよう。
(gemini) $ sudo mv /etc/network/interfaces.d/0010.br-external \
/etc/network/interfaces.d/0010.extsw
(gemini) $ sudo vi /etc/network/interfaces.d/0010.extsw
--ココから
auto br-external
allow-ovs br-external
iface br-external inet static
address 192.168.55.136
network 192.168.55.0
netmask 255.255.255.0
broadcast 192.168.55.255
gateway 192.168.55.1
ovs_type OVSBridge
ovs_ports ens3
dns-nameservers 192.168.55.1
↓
auto extsw
allow-ovs extsw
iface extsw inet static
address 192.168.55.136
network 192.168.55.0
netmask 255.255.255.0
broadcast 192.168.55.255
gateway 192.168.55.1
ovs_type OVSBridge
ovs_ports ens3
dns-nameservers 192.168.55.1
--ココまで
(gemini) $ sudo vi /etc/network/interfaces.d/0110.ens3
--ココから
auto ens3
allow-br-external
iface ens3 inet manual
ovs_bridge br-external
ovs_type OVSPort
↓
auto ens3
allow-extsw
iface ens3 inet manual
ovs_bridge extsw
ovs_type OVSPort
--ココまで
(gemini) $ sudo vi /etc/default/networking
--ココから
EXCLUDE_INTERFACES=br-external
↓
EXCLUDE_INTERFACES=extsw
--ココまで
(もし仮想マシンが作られていて動いていたら停止させておく必要がある)
(gemini ではまだ作成していないが、aquarius/sagittarius で作業を行う場合は要注意)
(gemini) $ virsh net-list --all
(gemini) $ virsh net-autostart --disable ovsbridge
(gemini) $ virsh net-destroy ovsbridge
(gemini) $ virsh net-list --all
(gemini) $ sudo ovs-vsctl show
(gemini) $ sudo ovs-vsctl add-br extsw
(gemini) $ sudo ovs-vsctl show
--ココからはコンソール作業
(gemini) $ sudo systemctl daemon-reload
(gemini) $ sudo systemctl stop networking
(gemini) $ sudo ovs-vsctl del-port br-external ens3
(gemini) $ sudo ovs-vsctl add-port extsw ens3
(gemini) $ sudo ovs-vsctl show
(gemini) $ sudo systemctl start networking
(gemini) $ sudo systemctl reboot
--コンソール作業ココまで
(gemini) $ ip address show br-external
(gemini) $ ip address show ens3
(gemini) $ ip address show extsw
(gemini) $ sudo ovs-vsctl del-br br-external
(gemini) $ sudo ovs-vsctl show
(gemini) $ virsh net-edit ovsbridge
--ココから
<bridge name='br-external'/>
↓
<bridge name='extsw'/>
--ココまで
(gemini) $ virsh net-autostart ovsbridge
(gemini) $ virsh net-start ovsbridge
(gemini) $ virsh net-list --all
(gemini) $ sudo systemctl reboot
これで終わりかな?
以下のコマンドを実行してみると分かるが、デバイス名に"-"が入っていると、その部分が"\x2d"という文字に置き換わってしまい、ちょっと見にくい。
(gemini) $ systemctl | grep external
(マウントポイントに"-"が入っている場合なども…)
なので、これの名前を"-"が入っていない内容に変更してみよう。
(gemini) $ sudo mv /etc/network/interfaces.d/0010.br-external \
/etc/network/interfaces.d/0010.extsw
(gemini) $ sudo vi /etc/network/interfaces.d/0010.extsw
--ココから
auto br-external
allow-ovs br-external
iface br-external inet static
address 192.168.55.136
network 192.168.55.0
netmask 255.255.255.0
broadcast 192.168.55.255
gateway 192.168.55.1
ovs_type OVSBridge
ovs_ports ens3
dns-nameservers 192.168.55.1
↓
auto extsw
allow-ovs extsw
iface extsw inet static
address 192.168.55.136
network 192.168.55.0
netmask 255.255.255.0
broadcast 192.168.55.255
gateway 192.168.55.1
ovs_type OVSBridge
ovs_ports ens3
dns-nameservers 192.168.55.1
--ココまで
(gemini) $ sudo vi /etc/network/interfaces.d/0110.ens3
--ココから
auto ens3
allow-br-external
iface ens3 inet manual
ovs_bridge br-external
ovs_type OVSPort
↓
auto ens3
allow-extsw
iface ens3 inet manual
ovs_bridge extsw
ovs_type OVSPort
--ココまで
(gemini) $ sudo vi /etc/default/networking
--ココから
EXCLUDE_INTERFACES=br-external
↓
EXCLUDE_INTERFACES=extsw
--ココまで
(もし仮想マシンが作られていて動いていたら停止させておく必要がある)
(gemini ではまだ作成していないが、aquarius/sagittarius で作業を行う場合は要注意)
(gemini) $ virsh net-list --all
(gemini) $ virsh net-autostart --disable ovsbridge
(gemini) $ virsh net-destroy ovsbridge
(gemini) $ virsh net-list --all
(gemini) $ sudo ovs-vsctl show
(gemini) $ sudo ovs-vsctl add-br extsw
(gemini) $ sudo ovs-vsctl show
--ココからはコンソール作業
(gemini) $ sudo systemctl daemon-reload
(gemini) $ sudo systemctl stop networking
(gemini) $ sudo ovs-vsctl del-port br-external ens3
(gemini) $ sudo ovs-vsctl add-port extsw ens3
(gemini) $ sudo ovs-vsctl show
(gemini) $ sudo systemctl start networking
(gemini) $ sudo systemctl reboot
--コンソール作業ココまで
(gemini) $ ip address show br-external
(gemini) $ ip address show ens3
(gemini) $ ip address show extsw
(gemini) $ sudo ovs-vsctl del-br br-external
(gemini) $ sudo ovs-vsctl show
(gemini) $ virsh net-edit ovsbridge
--ココから
<bridge name='br-external'/>
↓
<bridge name='extsw'/>
--ココまで
(gemini) $ virsh net-autostart ovsbridge
(gemini) $ virsh net-start ovsbridge
(gemini) $ virsh net-list --all
(gemini) $ sudo systemctl reboot
これで終わりかな?
2017年4月19日水曜日
ちょっとマテよ…(clvmd)
なんてこったい。
clvmパッケージはいくつかのファイルが含まれているけど、起動に関するファイルは主に以下の3つ。
ただ、1つ目もsystemdによって自動的に読み込まれる。
ただし、毎回起動に失敗している様子だった。
で、中身を読んでみたら…
/etc/init.d/clvm は /usr/sbin/clvmd を起動し、その後にクラスタLVMのアクティベートを行う。
対して /lib/systemd/system/lvm2-clvmd.service が clvmd の起動、
/lib/systemd/system/lvm2-cluster-activation.service が /lib/systemd/lvm2-cluster-activationを起動し、クラスタVGをアクティベートする、という機能だ。
つまり、 /etc/init.d/clvm の持つ2つの機能を、 lvm2-clvmd.service と lvm2-cluster-activation.service の2つで担っているというわけ。
だから、 /etc/init.d/clvm のサービスは起動する必要なし。起動しなくて正解だった。
また余計な時間をかけてしまった…。
--2017/04/20追記ココから--
だったら、 /etc/init.d/clvm は自動起動しないように設定しておけばいいんじゃないかな?
というわけで自動起動から外す。
(gemini) $ systemctl is-enabled clvm
(gemini) $ sudo systemctl disable clvm
(gemini) $ systemctl is-enabled clvm
再起動して確認
(gemini) $ sudo systemctl reboot
(gemini) $ dmesg
(gemini) $ systemctl status clvm
これで大丈夫だろう…。
--2017/04/20追記ココまで--
clvmパッケージはいくつかのファイルが含まれているけど、起動に関するファイルは主に以下の3つ。
- /etc/init.d/clvm
- /lib/systemd/system/lvm2-clvmd.service
- /lib/systemd/system/lvm2-cluster-activation.service
ただ、1つ目もsystemdによって自動的に読み込まれる。
ただし、毎回起動に失敗している様子だった。
で、中身を読んでみたら…
/etc/init.d/clvm は /usr/sbin/clvmd を起動し、その後にクラスタLVMのアクティベートを行う。
対して /lib/systemd/system/lvm2-clvmd.service が clvmd の起動、
/lib/systemd/system/lvm2-cluster-activation.service が /lib/systemd/lvm2-cluster-activationを起動し、クラスタVGをアクティベートする、という機能だ。
つまり、 /etc/init.d/clvm の持つ2つの機能を、 lvm2-clvmd.service と lvm2-cluster-activation.service の2つで担っているというわけ。
だから、 /etc/init.d/clvm のサービスは起動する必要なし。起動しなくて正解だった。
また余計な時間をかけてしまった…。
--2017/04/20追記ココから--
だったら、 /etc/init.d/clvm は自動起動しないように設定しておけばいいんじゃないかな?
というわけで自動起動から外す。
(gemini) $ systemctl is-enabled clvm
(gemini) $ sudo systemctl disable clvm
(gemini) $ systemctl is-enabled clvm
再起動して確認
(gemini) $ sudo systemctl reboot
(gemini) $ dmesg
(gemini) $ systemctl status clvm
これで大丈夫だろう…。
--2017/04/20追記ココまで--
2017年4月14日金曜日
Ubuntu 17.04リリース
Ubuntuの17.04がリリースされた模様。
このリリースはLTSではないので、一応16.04をメインに使っていくよ。
#デスクトップ用途なら17.04でもいいかも。
このリリースはLTSではないので、一応16.04をメインに使っていくよ。
#デスクトップ用途なら17.04でもいいかも。
2017年4月13日木曜日
dlm.confのマニュアル@超意訳&ぐぐる翻訳
dlm.confのマニュアルエントリを超意訳。ぐぐる翻訳も利用。
一部意味不明なのだけどご容赦。
---------------------------------------------------------------------------
DLM.CONF(5) dlm DLM.CONF(5)
NAME
SYNOPSIS
DESCRIPTION
Command line equivalents
コマンドラインオプションと同等の設定項目
Fencing
dlm 2012-04-09 DLM.CONF(5)
-------------------------------------------------------------------------------------
あと、コマンドラインオプション・confファイルへの記載可能項目の一覧意訳。
daemon_debug
--daemon_debug | -D
log_debug
--log_debug | -K
protocol
--protocol | -r str
debug_logfile
--debug_logfile | -L
enable_plock
--enable_plock | -p 0|1
plock_debug
--plock_debug | -P [0]
plock_rate_limit
--plock_rate_limit | -l int
plock_ownership
--plock_ownership | -o 0|1
drop_resources_time
--drop_resources_time | -t int
drop_resources_count
--drop_resources_count | -c int
drop_resources_age
--drop_resources_age | -a int
post_join_delay
--post_join_delay | -j int
enable_fencing
--enable_fencing | -f 0|1
enable_concurrent_fencing
--enable_concurrent_fencing 0|1
enable_startup_fencing
--enable_startup_fencing | -s 0|1
enable_quorum_fencing
--enable_quorum_fencing | -q 0|1
enable_quorum_lockspace
--enable_quorum_lockspace 0|1
--foreground
--fence_all str
--unfence_all
一部意味不明なのだけどご容赦。
---------------------------------------------------------------------------
DLM.CONF(5) dlm DLM.CONF(5)
NAME
dlm.conf - dlm_controld configuration file
SYNOPSIS
/etc/dlm/dlm.conf
DESCRIPTION
The configuration options in dlm.conf mirror the dlm_controld command line options.
The config file additionally allows advanced fencing and lockspace configuration that are not supported on the command line.
dlm.confへの記述は、dlm_controld コマンド行のオプションに反映されます。
また、dlm.confでは、コマンドラインでサポートされていない高度なフェンシングとロックスペースの設定も可能です。
The config file additionally allows advanced fencing and lockspace configuration that are not supported on the command line.
dlm.confへの記述は、dlm_controld コマンド行のオプションに反映されます。
また、dlm.confでは、コマンドラインでサポートされていない高度なフェンシングとロックスペースの設定も可能です。
Command line equivalents
コマンドラインオプションと同等の設定項目
If an option is specified on the command line and in the config file, the command line setting overrides the config file setting.
See dlm_controld(8) for descriptions and dlm_controld -h for defaults.
コマンドラインと設定ファイルの両方でオプションが指定されている場合、コマンドラインの設定が優先されます。
各オプションの説明についてはdlm_controld(8)、デフォルトについてはdlm_controld -hを参照してください。
Format:
key=val
Example:
log_debug=1
post_join_delay=10
protocol=tcp
Options:
daemon_debug
log_debug
protocol
debug_logfile
enable_plock
plock_debug
plock_rate_limit
plock_ownership
drop_resources_time
drop_resources_count
drop_resources_age
post_join_delay
enable_fencing
enable_concurrent_fencing
enable_startup_fencing
enable_quorum_fencing
enable_quorum_lockspace
See dlm_controld(8) for descriptions and dlm_controld -h for defaults.
コマンドラインと設定ファイルの両方でオプションが指定されている場合、コマンドラインの設定が優先されます。
各オプションの説明についてはdlm_controld(8)、デフォルトについてはdlm_controld -hを参照してください。
Format:
key=val
Example:
log_debug=1
post_join_delay=10
protocol=tcp
Options:
daemon_debug
log_debug
protocol
debug_logfile
enable_plock
plock_debug
plock_rate_limit
plock_ownership
drop_resources_time
drop_resources_count
drop_resources_age
post_join_delay
enable_fencing
enable_concurrent_fencing
enable_startup_fencing
enable_quorum_fencing
enable_quorum_lockspace
Fencing
A fence device definition begins with a device line, followed by a number of connect lines, one for each node connected to the device.
フェンスデバイスの定義はdevice行で始まり、接続数分の各ノードごとのconnect行が続きます。
A blank line separates device definitions.
空白行はデバイス定義を区切ります。
Devices are used in the order they are listed.
デバイスは、記載されている順序で使用されます。
The device key word is followed by a unique dev_name, the agent program to be used, and args, which are agent arguments specific to the device.
デバイスキーワードの後には、固有のdev_name、使用するエージェントプログラム、およびデバイス固有のエージェント引数が続きます。
The connect key word is followed by the dev_name of the device section, the node ID of the connected node in the format node=nodeid and args, which are agent arguments specific to the node for the given device.
connect行の後には、デバイスセクションのdev_name、接続ノードのノードID(node = nodeidおよびargsの形式)、指定されたデバイスのノードに固有のエージェント引数が続きます。
The format of args is key=val on both device and connect lines, each pair separated by a space, e.g. key1=val1 key2=val2 key3=val3.
argsの形式は、deviceとconnectの両方の行でkey = valの形式であり、各ペアはスペースで区切られています。例 key1 = val1 key2 = val2 key3 = val3。
Format:
device dev_name agent [args]
connect dev_name node=nodeid [args]
connect dev_name node=nodeid [args]
connect dev_name node=nodeid [args]
Example:
device foo fence_foo ipaddr=1.1.1.1 login=x password=y
connect foo node=1 port=1
connect foo node=2 port=2
connect foo node=3 port=3
device bar fence_bar ipaddr=2.2.2.2 login=x password=y
connect bar node=1 port=1
connect bar node=2 port=2
connect bar node=3 port=3
フェンスデバイスの定義はdevice行で始まり、接続数分の各ノードごとのconnect行が続きます。
A blank line separates device definitions.
空白行はデバイス定義を区切ります。
Devices are used in the order they are listed.
デバイスは、記載されている順序で使用されます。
The device key word is followed by a unique dev_name, the agent program to be used, and args, which are agent arguments specific to the device.
デバイスキーワードの後には、固有のdev_name、使用するエージェントプログラム、およびデバイス固有のエージェント引数が続きます。
The connect key word is followed by the dev_name of the device section, the node ID of the connected node in the format node=nodeid and args, which are agent arguments specific to the node for the given device.
connect行の後には、デバイスセクションのdev_name、接続ノードのノードID(node = nodeidおよびargsの形式)、指定されたデバイスのノードに固有のエージェント引数が続きます。
The format of args is key=val on both device and connect lines, each pair separated by a space, e.g. key1=val1 key2=val2 key3=val3.
argsの形式は、deviceとconnectの両方の行でkey = valの形式であり、各ペアはスペースで区切られています。例 key1 = val1 key2 = val2 key3 = val3。
Format:
device dev_name agent [args]
connect dev_name node=nodeid [args]
connect dev_name node=nodeid [args]
connect dev_name node=nodeid [args]
Example:
device foo fence_foo ipaddr=1.1.1.1 login=x password=y
connect foo node=1 port=1
connect foo node=2 port=2
connect foo node=3 port=3
device bar fence_bar ipaddr=2.2.2.2 login=x password=y
connect bar node=1 port=1
connect bar node=2 port=2
connect bar node=3 port=3
Parallel devices
Some devices, like dual power or dual path, must all be turned off in parallel for fencing to succeed.
To define multiple devices as being parallel to each other, use the same base dev_name with different suffixes and a colon separator between base name and suffix.
デュアルパワーまたはデュアルパスのようなデバイスの中には、フェンシングを成功させるためにすべて並列にオフにする必要があるものがあります。
複数のデバイスを互いに並列に定義するには、同じbase dev_nameと異なるsuffixを使用し、コロン区切り文字をベース名とsuffixの間に使用します。
Format:
device dev_name:1 agent [args]
connect dev_name:1 node=nodeid [args]
connect dev_name:1 node=nodeid [args]
connect dev_name:1 node=nodeid [args]
device dev_name:2 agent [args]
connect dev_name:2 node=nodeid [args]
connect dev_name:2 node=nodeid [args]
connect dev_name:2 node=nodeid [args]
Example:
device foo:1 fence_foo ipaddr=1.1.1.1 login=x password=y
connect foo:1 node=1 port=1
connect foo:2 node=2 port=2
connect foo:3 node=3 port=3
device foo:2 fence_foo ipaddr=5.5.5.5 login=x password=y
connect foo:2 node=1 port=1
connect foo:2 node=2 port=2
connect foo:2 node=3 port=3
To define multiple devices as being parallel to each other, use the same base dev_name with different suffixes and a colon separator between base name and suffix.
デュアルパワーまたはデュアルパスのようなデバイスの中には、フェンシングを成功させるためにすべて並列にオフにする必要があるものがあります。
複数のデバイスを互いに並列に定義するには、同じbase dev_nameと異なるsuffixを使用し、コロン区切り文字をベース名とsuffixの間に使用します。
Format:
device dev_name:1 agent [args]
connect dev_name:1 node=nodeid [args]
connect dev_name:1 node=nodeid [args]
connect dev_name:1 node=nodeid [args]
device dev_name:2 agent [args]
connect dev_name:2 node=nodeid [args]
connect dev_name:2 node=nodeid [args]
connect dev_name:2 node=nodeid [args]
Example:
device foo:1 fence_foo ipaddr=1.1.1.1 login=x password=y
connect foo:1 node=1 port=1
connect foo:2 node=2 port=2
connect foo:3 node=3 port=3
device foo:2 fence_foo ipaddr=5.5.5.5 login=x password=y
connect foo:2 node=1 port=1
connect foo:2 node=2 port=2
connect foo:2 node=3 port=3
Unfencing
A node may sometimes need to "unfence" itself when starting.
The unfencing command reverses the effect of a previous fencing operation against it.
An example would be fencing that disables a port on a SAN switch.
A node could use unfencing to re-enable its switch port when starting up after rebooting.
(Care must be taken to ensure it's safe for a node to unfence itself.
A node often needs to be cleanly rebooted before unfencing itself.)
ノードは、起動時に「unfence」する必要があることがあります。
unfencingコマンドは、以前のフェンシング操作の効果を元に戻します。
例えば、フェンシングによってSANスイッチ上のポートをdisableにした場合等で必要になります。
この場合、ノードが再起動後に、スイッチング・ポートを再び有効にするためにunfencingを使用します。
(ノードは、安全に自身をunfenceする必要があります。
状況によっては、ノードをunfenceする前に、そのノードを再起動(クリーンブート)する必要があります。)
To specify that a node should unfence itself for a given device, the unfence line is added after the connect lines.
特定のデバイスでノードがunfenceされないように指定するには、connect行の後にunfence行を追加します。
Format:
device dev_name agent [args]
connect dev_name node=nodeid [args]
connect dev_name node=nodeid [args]
connect dev_name node=nodeid [args]
unfence dev_name
Example:
device foo fence_foo ipaddr=1.1.1.1 login=x password=y
connect foo node=1 port=1
connect foo node=2 port=2
connect foo node=3 port=3
unfence foo
The unfencing command reverses the effect of a previous fencing operation against it.
An example would be fencing that disables a port on a SAN switch.
A node could use unfencing to re-enable its switch port when starting up after rebooting.
(Care must be taken to ensure it's safe for a node to unfence itself.
A node often needs to be cleanly rebooted before unfencing itself.)
ノードは、起動時に「unfence」する必要があることがあります。
unfencingコマンドは、以前のフェンシング操作の効果を元に戻します。
例えば、フェンシングによってSANスイッチ上のポートをdisableにした場合等で必要になります。
この場合、ノードが再起動後に、スイッチング・ポートを再び有効にするためにunfencingを使用します。
(ノードは、安全に自身をunfenceする必要があります。
状況によっては、ノードをunfenceする前に、そのノードを再起動(クリーンブート)する必要があります。)
To specify that a node should unfence itself for a given device, the unfence line is added after the connect lines.
特定のデバイスでノードがunfenceされないように指定するには、connect行の後にunfence行を追加します。
Format:
device dev_name agent [args]
connect dev_name node=nodeid [args]
connect dev_name node=nodeid [args]
connect dev_name node=nodeid [args]
unfence dev_name
Example:
device foo fence_foo ipaddr=1.1.1.1 login=x password=y
connect foo node=1 port=1
connect foo node=2 port=2
connect foo node=3 port=3
unfence foo
Simple devices
In some cases, a single fence device is used for all nodes, and it requires no node-specific args.
This would typically be a "bridge" fence device in which an agent is passing a fence request to another subsystem to handle.
(Note that a "node=nodeid" arg is always automatically included in agent args, so a node-specific nodeid is always present to minimally identify the victim.)
よくあるケースとして、単一のフェンスデバイスがすべてのノードで使用され、ノード固有のパラメータが必要無い、という構成があります。
これは、典型的には、エージェントがフェンス要求を別のサブシステムに渡して処理する「ブリッジ」フェンス装置として機能する場合です。
(fencing対象を識別するために、"node = nodeid"引数は常にagent引数に自動的に含まれます。そのため、ノード固有のnodeidは必ず作成されます。)
In such a case, a simplified, single-line fence configuration is possible, with format:
最も単純なfence構成は、以下のように1行で記載することが可能です。
fence_all agent [args]
Example:
fence_all dlm_stonith
A fence_all configuration is not compatible with a fence device configuration (above).
fence_all設定はフェンスデバイス設定(上記)と互換性がありません。
Unfencing can optionally be applied with:
アンフェンシングは、オプションで次のように指定できます。
fence_all agent [args]
unfence_all
Lockspace configurationThis would typically be a "bridge" fence device in which an agent is passing a fence request to another subsystem to handle.
(Note that a "node=nodeid" arg is always automatically included in agent args, so a node-specific nodeid is always present to minimally identify the victim.)
よくあるケースとして、単一のフェンスデバイスがすべてのノードで使用され、ノード固有のパラメータが必要無い、という構成があります。
これは、典型的には、エージェントがフェンス要求を別のサブシステムに渡して処理する「ブリッジ」フェンス装置として機能する場合です。
(fencing対象を識別するために、"node = nodeid"引数は常にagent引数に自動的に含まれます。そのため、ノード固有のnodeidは必ず作成されます。)
In such a case, a simplified, single-line fence configuration is possible, with format:
最も単純なfence構成は、以下のように1行で記載することが可能です。
fence_all agent [args]
Example:
fence_all dlm_stonith
A fence_all configuration is not compatible with a fence device configuration (above).
fence_all設定はフェンスデバイス設定(上記)と互換性がありません。
Unfencing can optionally be applied with:
アンフェンシングは、オプションで次のように指定できます。
fence_all agent [args]
unfence_all
A lockspace definition begins with a lockspace line, followed by a number of master lines.
A blank line separates lockspace definitions.
ロック・スペースの定義は、lockspace行から始まり、その後にいくつかのmaster行が続きます。
空白行は、ロック・スペース定義を区切ります。
Format:
lockspace ls_name [ls_args]
master ls_name node=nodeid [node_args]
master ls_name node=nodeid [node_args]
master ls_name node=nodeid [node_args]
A blank line separates lockspace definitions.
ロック・スペースの定義は、lockspace行から始まり、その後にいくつかのmaster行が続きます。
空白行は、ロック・スペース定義を区切ります。
Format:
lockspace ls_name [ls_args]
master ls_name node=nodeid [node_args]
master ls_name node=nodeid [node_args]
master ls_name node=nodeid [node_args]
Disabling resource directory
リソースディレクトリを無効にする
リソースディレクトリを無効にする
Lockspaces usually use a resource directory to keep track of which node is the master of each resource.
The dlm can operate without the resource directory, though, by statically assigning the master of a resource using a hash of the resource name.
To enable, set the perlockspace nodir option to 1.
ロックスペースは通常、リソースディレクトリを使用して、どのノードが各リソースのマスターであるかを追跡します。
ただし、リソース名のハッシュを使用してリソースのマスターを静的に割り当てることによって、dlmはリソース・ディレクトリーなしで動作することができます。
有効にするには、perlockspace nodirオプションを1に設定します。
Example:
lockspace foo nodir=1
The dlm can operate without the resource directory, though, by statically assigning the master of a resource using a hash of the resource name.
To enable, set the perlockspace nodir option to 1.
ロックスペースは通常、リソースディレクトリを使用して、どのノードが各リソースのマスターであるかを追跡します。
ただし、リソース名のハッシュを使用してリソースのマスターを静的に割り当てることによって、dlmはリソース・ディレクトリーなしで動作することができます。
有効にするには、perlockspace nodirオプションを1に設定します。
Example:
lockspace foo nodir=1
Lock-server configuration
ロックサーバー構成
ロックサーバー構成
The nodir setting can be combined with node weights to create a configuration where select node(s) are the master of all resources/locks.
These master nodes can be viewed as "lock servers" for the other nodes.
ノード設定をノード加重と組み合わせて、選択ノードがすべてのリソース/ロックのマスターである構成を作成することができます。
これらのマスターノードは、他のノードの「ロックサーバー」とみなすことができます。
Example of nodeid 1 as master of all resources:
すべてのリソースのマスターであるnodeid 1の例:
lockspace foo nodir=1
master foo node=1
Example of nodeid's 1 and 2 as masters of all resources:
すべてのリソースのマスターとしてのnodeidの1と2の例:
lockspace foo nodir=1
master foo node=1
master foo node=2
Lock management will be partitioned among the available masters.
There can be any number of masters defined.
The designated master nodes will master all resources/locks (according to the resource name hash).
When no masters are members of the lockspace, then the nodes revert to the common fully-distributed configuration.
Recovery is faster, with little disruption, when a non-master node joins/leaves.
ロック管理は、使用可能なマスター間で分割されます。
任意の数のマスタを定義することができます。
指定されたマスターノードは、すべてのリソース/ロックをマスターします(リソース名ハッシュに従って)。
マスターがロックスペースのメンバーでない場合、ノードは共通の完全分散構成に戻ります。
マスターノードではないノードが参加/離脱するときに、リカバリは高速で、中断はほとんどありません。
There is no special mode in the dlm for this lock server configuration, it's just a natural consequence of combining the "nodir" option with node weights.
When a lockspace has master nodes defined, the master has a default weight of 1 and all non-master nodes have weight of 0.
An explicit non-zero weight can also be assigned to master nodes, e.g.
このロック・サーバー構成では、dlmに特別なモードはありません。ノードの重みと "nodir"オプションを組み合わせるのは当然の結果です。
ロック・スペースにマスター・ノードが定義されている場合、マスターのデフォルト重みは1で、非マスター・ノードの重みはすべて0です。
明示的な非ゼロ加重値をマスターノードに割り当てることもできます。
lockspace foo nodir=1
master foo node=1 weight=2
master foo node=2 weight=1
In which case node 1 will master 2/3 of the total resources and node 2 will master the other 1/3.
この場合、ノード1は総リソースの2/3を習得し、ノード2はもう1/3を習得します。
SEE ALSOThese master nodes can be viewed as "lock servers" for the other nodes.
ノード設定をノード加重と組み合わせて、選択ノードがすべてのリソース/ロックのマスターである構成を作成することができます。
これらのマスターノードは、他のノードの「ロックサーバー」とみなすことができます。
Example of nodeid 1 as master of all resources:
すべてのリソースのマスターであるnodeid 1の例:
lockspace foo nodir=1
master foo node=1
Example of nodeid's 1 and 2 as masters of all resources:
すべてのリソースのマスターとしてのnodeidの1と2の例:
lockspace foo nodir=1
master foo node=1
master foo node=2
Lock management will be partitioned among the available masters.
There can be any number of masters defined.
The designated master nodes will master all resources/locks (according to the resource name hash).
When no masters are members of the lockspace, then the nodes revert to the common fully-distributed configuration.
Recovery is faster, with little disruption, when a non-master node joins/leaves.
ロック管理は、使用可能なマスター間で分割されます。
任意の数のマスタを定義することができます。
指定されたマスターノードは、すべてのリソース/ロックをマスターします(リソース名ハッシュに従って)。
マスターがロックスペースのメンバーでない場合、ノードは共通の完全分散構成に戻ります。
マスターノードではないノードが参加/離脱するときに、リカバリは高速で、中断はほとんどありません。
There is no special mode in the dlm for this lock server configuration, it's just a natural consequence of combining the "nodir" option with node weights.
When a lockspace has master nodes defined, the master has a default weight of 1 and all non-master nodes have weight of 0.
An explicit non-zero weight can also be assigned to master nodes, e.g.
このロック・サーバー構成では、dlmに特別なモードはありません。ノードの重みと "nodir"オプションを組み合わせるのは当然の結果です。
ロック・スペースにマスター・ノードが定義されている場合、マスターのデフォルト重みは1で、非マスター・ノードの重みはすべて0です。
明示的な非ゼロ加重値をマスターノードに割り当てることもできます。
lockspace foo nodir=1
master foo node=1 weight=2
master foo node=2 weight=1
In which case node 1 will master 2/3 of the total resources and node 2 will master the other 1/3.
この場合、ノード1は総リソースの2/3を習得し、ノード2はもう1/3を習得します。
dlm_controld(8), dlm_tool(8)
dlm 2012-04-09 DLM.CONF(5)
-------------------------------------------------------------------------------------
あと、コマンドラインオプション・confファイルへの記載可能項目の一覧意訳。
daemon_debug
--daemon_debug | -D
enable debugging to stderr and don't fork [0]
stderrへのデバッグを有効にし、forkしません。
stderrへのデバッグを有効にし、forkしません。
log_debug
--log_debug | -K
enable kernel dlm debugging messages [0]
カーネルdlmデバッグメッセージを有効にします。
カーネルdlmデバッグメッセージを有効にします。
protocol
--protocol | -r str
dlm kernel lowcomms protocol: tcp, sctp, detect [detect]
dlmカーネルローコムプロトコル:tcp、sctp、detect。
dlmカーネルローコムプロトコル:tcp、sctp、detect。
debug_logfile
--debug_logfile | -L
write debugging to log file [0]
ログファイルにデバッグを書き込みます。
ログファイルにデバッグを書き込みます。
enable_plock
--enable_plock | -p 0|1
enable/disable posix lock support for cluster fs [1]
クラスタfsに対するposixロックのサポートを有効または無効にします。
クラスタfsに対するposixロックのサポートを有効または無効にします。
plock_debug
--plock_debug | -P [0]
enable plock debugging
plockのデバッグを可能にする。
plockのデバッグを可能にする。
plock_rate_limit
--plock_rate_limit | -l int
limit rate of plock operations (0 for none) [0]
plock操作の制限速度(0の場合は無し)。
plock操作の制限速度(0の場合は無し)。
plock_ownership
--plock_ownership | -o 0|1
enable/disable plock ownership [0]
plockの所有権を有効/無効にします。
plockの所有権を有効/無効にします。
drop_resources_time
--drop_resources_time | -t int
plock ownership drop resources time (milliseconds) [10000]
plockの所有権ドロップリソース時間(ミリ秒)。
plockの所有権ドロップリソース時間(ミリ秒)。
drop_resources_count
--drop_resources_count | -c int
plock ownership drop resources count [10]
plockの所有権ドロップリソースの数。
plockの所有権ドロップリソースの数。
drop_resources_age
--drop_resources_age | -a int
plock ownership drop resources age (milliseconds) [10000]
plock所有権ドロップリソースの経過時間(ミリ秒)。
plock所有権ドロップリソースの経過時間(ミリ秒)。
post_join_delay
--post_join_delay | -j int
seconds to delay fencing after cluster join [30]
クラスタ参加後のフェンシングを遅らせる秒数。
クラスタ参加後のフェンシングを遅らせる秒数。
enable_fencing
--enable_fencing | -f 0|1
enable/disable fencing [1]
フェンシングを有効/無効にします。
フェンシングを有効/無効にします。
enable_concurrent_fencing
--enable_concurrent_fencing 0|1
enable/disable concurrent fencing [0]
同時フェンシングを有効/無効にします。
同時フェンシングを有効/無効にします。
enable_startup_fencing
--enable_startup_fencing | -s 0|1
enable/disable startup fencing [1]
起動フェンシングを有効/無効にします。
起動フェンシングを有効/無効にします。
enable_quorum_fencing
--enable_quorum_fencing | -q 0|1
enable/disable quorum requirement for fencing [1]
フェンシングのための定足数要件を有効/無効にします。
フェンシングのための定足数要件を有効/無効にします。
enable_quorum_lockspace
--enable_quorum_lockspace 0|1
enable/disable quorum requirement for lockspace operations [1]
ロックスペース操作のクォーラム要件を有効/無効にします。
ロックスペース操作のクォーラム要件を有効/無効にします。
--foreground
don't fork [0]
フォークしないでください。
フォークしないでください。
--fence_all str
fence all nodes with this agent
すべてのノードをこのエージェントにフェンスします。
すべてのノードをこのエージェントにフェンスします。
--unfence_all
enable unfencing self with fence_all agent
fence_allエージェントで自己フェンシングを有効にします。
fence_allエージェントで自己フェンシングを有効にします。
2017年4月7日金曜日
今の調査状況
--2017/04/20追記ココから--
ここで出ている問題は、前回分に追記した内容で解消したっぽい。
なので、無駄な記事になってしまった。
--2017/04/20追記ココまで--
全然解決しねぇ。
ここで出ている問題は、前回分に追記した内容で解消したっぽい。
なので、無駄な記事になってしまった。
--2017/04/20追記ココまで--
全然解決しねぇ。
今のところ…
- corosyncの自動起動にほぼ間違いなく失敗する。
- corosyncの自動起動失敗に伴い、dlmも停止する。
- o2cbの起動もほぼ間違いなく失敗する。
(ただし、systemd的には成功しているように見える。) - OSの起動後、手作業でcorosyncを起動することは可能。
- 同、手作業でdlmを起動することは可能。
(corosyncが起動していない状態でdlmを手作業で起動すれば、corosyncも連動して起動する。) - corosyncのsystemd起動ファイル(/lib/systemd/system/corosync.service)のRequiresとAfterにopenvswitch-switchを追加することで、corosync/dlmの自動起動成功率は高まる。
(必ず成功するわけではなく、自動起動失敗することもある。) - 両ノードでdlmが起動している状態で、片方のノードを停止させると、しばらくしてから生きている方のノードも自動でリブートする。
- OS起動後、o2cbを手作業で起動(停止してから起動)は成功する。
- corosync/dlmが停止している(起動失敗している)状態で、手作業でgfs2ファイルシステムをマウントしようとすると、corosync/dlmが自動起動してマウント成功する。
- o2cbが正常起動している状態でなら、ocfs2ファイルシステムのマウントが可能。
- o2cbの起動が上手く行っていない状態でocfs2ファイルシステムをマウントしようとすると、マウント失敗する。
- o2cbを正常停止させている状態からocfs2ファイルシステムをマウントしようとすると、o2cbが自動起動してマウント成功する。
- いずれも、openvswitch-switchが導入されていない環境では起きない問題。
辺りのことが分かってきた。
考え方的に、corosync/dlmとgfs2はセット、o2cbとocfs2がセット、となる。
今は両方に問題が出ているが、別モノとして整理、調査しないと混乱してしまうな。
考え方的に、corosync/dlmとgfs2はセット、o2cbとocfs2がセット、となる。
今は両方に問題が出ているが、別モノとして整理、調査しないと混乱してしまうな。
2017年4月4日火曜日
共有仮想ディスクの設定
前回、cancer側でocfs2ファイルシステムのマウントが出来なくなった、と書いた。
クラスタ云々っていう理由だと思ったけど、それ以前に共有仮想ディスク(/dev/vdb、/dev/vdc)の設定自体がおかしかった。
そもそも、複数のサーバで仮想ディスクを共有させるのなら、仮想マシンにそのディスクを割り当てる時に「共有可能」というチェックボックスにチェックを入れておく必要があった。
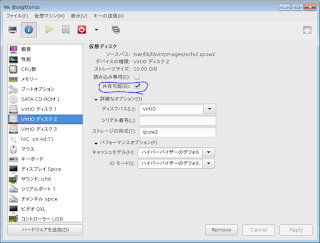
この時点で既に設定が間違っていたということになる。
これが付いていないと、それぞれの仮想マシン(gemini/cancer)でスナップショットを作成したりすると、この仮想ディスクも2世代スナップショットが作られてしまい、内部的に混乱してしまう。
それで、geminiでマウント出来ても、cancerでマウント出来ない状態になったようだ。
アカン…もう一度作り直すか…。
クラスタ云々っていう理由だと思ったけど、それ以前に共有仮想ディスク(/dev/vdb、/dev/vdc)の設定自体がおかしかった。
そもそも、複数のサーバで仮想ディスクを共有させるのなら、仮想マシンにそのディスクを割り当てる時に「共有可能」というチェックボックスにチェックを入れておく必要があった。

この時点で既に設定が間違っていたということになる。
これが付いていないと、それぞれの仮想マシン(gemini/cancer)でスナップショットを作成したりすると、この仮想ディスクも2世代スナップショットが作られてしまい、内部的に混乱してしまう。
それで、geminiでマウント出来ても、cancerでマウント出来ない状態になったようだ。
アカン…もう一度作り直すか…。
2017年4月2日日曜日
ocfs2とdlm
結局、gemini/cancerの作り直しをしているのだが…。
そこでちょっとおかしなことに気付いた。
共有ファイルシステム(ocfs2)では、gemini/cancerともにocfs2関連のパッケージのインストールとそのセットアップで共有ファイルシステムが実現できていたが、その後geminiにcorosync/dlm関連のパッケージを導入したら、cancer側でocfs2のファイルシステムマウントが出来なくなった。
cancer側でマウントしようとすると、「このファイルシステムはクラスタに所属している」というメッセージが出て、マウントできないのだ。
で、なんでだろうかと調べていたら、gemini側でocfs2ファイルシステムをマウントしようとすると、syslogにdlm関連のメッセージが出力される。
ocfs2とdlmは完全に独立していて、相互関連は無いと思っていたのだが、どうやら関連があるようだ。
元々調査していた問題とは別だけど、こちらはこちらで調査することにする。
--2017/04/20追記ココから--
この問題は、 gemini/cancer で仮想ディスクを共有したままスナップショットを作成したり戻したり、というのが原因だったようだ。
今後、スナップショットを取る時には、
仮想マシンの停止
↓
共有仮想ディスクの切り離し
↓
スナップショットを作成
↓
共有仮想マシンの接続
↓
仮想マシンの起動
という流れを取ることにしよう…。
--2017/04/20追記ココまで--
そこでちょっとおかしなことに気付いた。
共有ファイルシステム(ocfs2)では、gemini/cancerともにocfs2関連のパッケージのインストールとそのセットアップで共有ファイルシステムが実現できていたが、その後geminiにcorosync/dlm関連のパッケージを導入したら、cancer側でocfs2のファイルシステムマウントが出来なくなった。
cancer側でマウントしようとすると、「このファイルシステムはクラスタに所属している」というメッセージが出て、マウントできないのだ。
で、なんでだろうかと調べていたら、gemini側でocfs2ファイルシステムをマウントしようとすると、syslogにdlm関連のメッセージが出力される。
ocfs2とdlmは完全に独立していて、相互関連は無いと思っていたのだが、どうやら関連があるようだ。
元々調査していた問題とは別だけど、こちらはこちらで調査することにする。
--2017/04/20追記ココから--
この問題は、 gemini/cancer で仮想ディスクを共有したままスナップショットを作成したり戻したり、というのが原因だったようだ。
今後、スナップショットを取る時には、
仮想マシンの停止
↓
共有仮想ディスクの切り離し
↓
スナップショットを作成
↓
共有仮想マシンの接続
↓
仮想マシンの起動
という流れを取ることにしよう…。
--2017/04/20追記ココまで--
登録:
投稿 (Atom)